上海信息化文獻(xiàn)知識發(fā)現(xiàn)
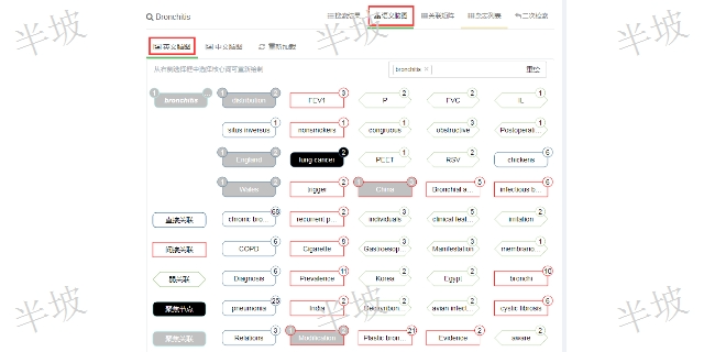
文本語義腦圖基本原理1,、以讀者當(dāng)前搜索詞作為啟始節(jié)點(diǎn)(一起始列),,后續(xù)(右側(cè))的第n列數(shù)據(jù)是由前n-1列的節(jié)點(diǎn)元素概念之間語義關(guān)聯(lián)推導(dǎo)而得,。2、共有4種不同的節(jié)點(diǎn)類型:中心節(jié)點(diǎn)(a),直接關(guān)聯(lián)節(jié)點(diǎn)(b),間接關(guān)聯(lián)節(jié)點(diǎn)(c),弱關(guān)聯(lián)節(jié)點(diǎn)(d),。從搜索詞(a)出發(fā),,體現(xiàn)a推導(dǎo)b,b推導(dǎo)c,c推導(dǎo)d的上下層級關(guān)聯(lián)(啟發(fā)式知識關(guān)聯(lián)揭示),。3、單一列向量空間內(nèi),,由上至下所有節(jié)點(diǎn)之間依據(jù)該文本概念詞的語義權(quán)重和文獻(xiàn)時(shí)序權(quán)重排序(語義概念權(quán)重有序),。4、任意概念節(jié)點(diǎn)右上數(shù)字角標(biāo)表示其在當(dāng)前Top-N搜索結(jié)果中的文獻(xiàn)數(shù),。點(diǎn)擊該文獻(xiàn)數(shù)則鏈接至相應(yīng)的命中文獻(xiàn)(文本概念的細(xì)分聚類及其迅速定位),。5、選擇語義腦圖中任意節(jié)點(diǎn)(x)作為興趣點(diǎn)(聚焦節(jié)點(diǎn)),,可以進(jìn)一步推導(dǎo)出該節(jié)點(diǎn)的所有直接關(guān)聯(lián)節(jié)點(diǎn)(y),。(隱形識發(fā)現(xiàn))6、興趣聚焦操作時(shí)(x-y)左上角標(biāo)指引聚焦關(guān)聯(lián)文獻(xiàn),。7,、任意節(jié)點(diǎn)可以作為新的起始中心節(jié)點(diǎn)(a),重構(gòu)一幅全新的語義腦圖(擴(kuò)散思維),。8,、跨語言搜索時(shí),系統(tǒng)可以同時(shí)分別生成中文和英文兩張語義腦圖,。文獻(xiàn)資源可以在哪里查到,?上海信息化文獻(xiàn)知識發(fā)現(xiàn)
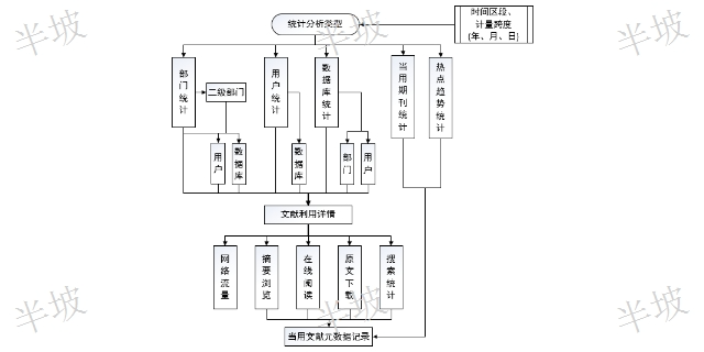
二次文獻(xiàn)(secondarydocument):是指文獻(xiàn)工作者對一次文獻(xiàn)進(jìn)行加工,、提煉和壓縮之后所得到的產(chǎn)物,,是為了便于管理和利用一次文獻(xiàn)而編輯、出版和累積起來的工具性文獻(xiàn),。檢索工具書和網(wǎng)上檢索引擎是典型的二次文獻(xiàn),。三次文獻(xiàn)(tertiarydocument):是指對有關(guān)的一次文獻(xiàn)和二次文獻(xiàn)進(jìn)行入的分析研究綜合概括而成的產(chǎn)物。如大百科全書,、辭典,、電子百科等。檢索狹義的檢索(Retrieval)是指依據(jù)一定的方法,,從已經(jīng)組織好的大量有關(guān)文獻(xiàn)中,,查找并獲取特定的相關(guān)文獻(xiàn)的過程。這里的文獻(xiàn),,不是通常所指的文獻(xiàn)本身,,而是關(guān)于文獻(xiàn)的信息或文獻(xiàn)的線索。廣義的檢索包括信息的存儲和檢索兩個(gè)過程(StorageandRetrieval),。河南文獻(xiàn)知識發(fā)現(xiàn)聯(lián)系人上海半坡的遠(yuǎn)程訪問服務(wù)能夠促使圖書館現(xiàn)有數(shù)字文獻(xiàn)館藏發(fā)揮更大的讀者服務(wù)效益,。
文獻(xiàn)數(shù)據(jù)庫簡介一、定義及分類:文獻(xiàn)數(shù)據(jù)庫,,是指計(jì)算機(jī)可讀的,、有組織的相關(guān)文獻(xiàn)信息的**,。按照國別分:可分為外文文獻(xiàn)數(shù)據(jù)庫及中文文獻(xiàn)數(shù)據(jù)庫按照信息類別可分為:期刊論文數(shù)據(jù)庫、**數(shù)據(jù)庫,、會(huì)議論文數(shù)據(jù)庫,、學(xué)位論文數(shù)據(jù)庫……;按照學(xué)科領(lǐng)域分類,,例如生命科學(xué)領(lǐng)域有PubMed數(shù)據(jù)庫,,工程技術(shù)領(lǐng)域有EI數(shù)據(jù)庫,化學(xué)領(lǐng)域的SciFinder,Reaxys,F1000,NANO數(shù)據(jù)庫,;按照信息類型可分為:全文數(shù)據(jù)庫及文摘數(shù)據(jù)庫,。1)中文全文數(shù)據(jù)庫舉例:2)英文全文數(shù)據(jù)庫舉例:3)文摘數(shù)據(jù)庫二.文摘數(shù)據(jù)庫與全文數(shù)據(jù)庫的比較二者主要區(qū)別在于用戶在全文數(shù)據(jù)庫中可以直接下載文獻(xiàn),而文摘型數(shù)據(jù)庫只提供了全文鏈接,,無法下載全文,,用戶需要點(diǎn)擊鏈接前往期刊官網(wǎng)進(jìn)行下載。
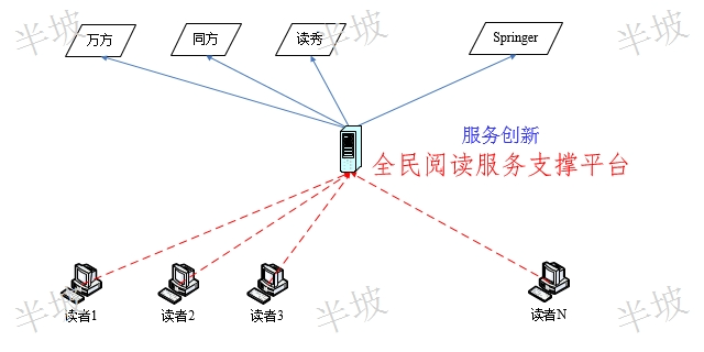
數(shù)據(jù)庫作為一種“宏文本”,。數(shù)據(jù)庫收錄的數(shù)字化文本,,文本性質(zhì)并沒有改變。每個(gè)數(shù)據(jù)庫都可以看作一種**文本,,不同的文本基于知識,、邏輯、功能等被聯(lián)結(jié)成為巨大文本,,是別集,、總集、類書,、叢書等傳統(tǒng)文獻(xiàn)形態(tài)的革新,。單一、直接的文本閱讀銳減,,取而代之的是數(shù)據(jù)庫形態(tài)的龐大的文本**,。檢索界限消失后,古籍?dāng)?shù)據(jù)庫可以很大程度地“一站式”獲取所需文獻(xiàn)資料,。關(guān)系型智能化的數(shù)據(jù)庫作為一種文本,,其形態(tài)與功能較紙本時(shí)代有質(zhì)的提升。歷史文本的空間化與可視化,??梢暬軌虬嘀刈兞浚哂锌勺x性與可理解性,。地理信息系統(tǒng)(GIS)技術(shù)***地促進(jìn)了傳統(tǒng)文獻(xiàn)的圖表化,、可視化,以動(dòng)態(tài)的數(shù)字化地圖和知識圖譜體系,,改變和豐富了傳統(tǒng)的文本形態(tài)和使用功能,?!耙粓D勝千言”,文本內(nèi)部蘊(yùn)含的信息也具有可視化潛力,。通過發(fā)現(xiàn)古代漢語文本特定的詞頻模式(如高頻詞,、異常詞頻),可以借助文檔相似性比較,、主題探測,、趨勢發(fā)現(xiàn)等探索文本中特定的隱含語義關(guān)系,將難以理解的抽象數(shù)據(jù)空間轉(zhuǎn)化成具體直觀的視覺空間,。查詢文獻(xiàn)知識需要付費(fèi)嗎,?
文本語義腦圖(Text Mind Map)為輔助讀者研判一篇文獻(xiàn)的相關(guān)性,檢索系統(tǒng)通常會(huì)針對某一文獻(xiàn)內(nèi)容特征進(jìn)行單一維度的文獻(xiàn)聚類細(xì)分,。例如:依據(jù)關(guān)鍵詞或者依據(jù)作者對檢出文獻(xiàn)進(jìn)行再聚類并揭示其所對應(yīng)的相關(guān)文獻(xiàn),。 文本語義腦圖突破傳統(tǒng)搜索引擎查詢結(jié)果單維列表呈現(xiàn)的局限性,以讀者搜索詞為起點(diǎn),,形成一個(gè)m行乘n列的文本語義概念的關(guān)聯(lián)矩陣表達(dá),。其目的是輔助讀者發(fā)現(xiàn)搜索結(jié)果內(nèi)的文本概念之間的隱性知識關(guān)聯(lián)以及拓展讀者啟發(fā)式發(fā)散思維。怎么查找文獻(xiàn)關(guān)聯(lián)的知識內(nèi)容,?網(wǎng)絡(luò)文獻(xiàn)知識發(fā)現(xiàn)用戶體驗(yàn)
文獻(xiàn)知識到底是什么,?上海信息化文獻(xiàn)知識發(fā)現(xiàn)
早期的文獻(xiàn)一般是通過口頭交談、參觀展覽,、參加報(bào)告會(huì)等途徑獲取,,不僅在內(nèi)容上有一定的價(jià)值,而且能彌補(bǔ)一般公開文獻(xiàn)從信息的客觀形成到公開傳播之間費(fèi)時(shí)甚多的弊病,。它是指未經(jīng)過任何加工的原始文獻(xiàn),,如實(shí)驗(yàn)記錄,、手稿,、原始錄音、原始錄像,、談話記錄等,。零次文獻(xiàn)在原始文獻(xiàn)的保存、原始數(shù)據(jù)的核對,、原始構(gòu)思的核定(權(quán)利人)等方面有著重要的作用,。接下來,我們了解一下一次文獻(xiàn)的概念一次文獻(xiàn)(primarydocument):是指作者以本人的研究成果為基本素材而創(chuàng)作或撰寫的文獻(xiàn),,不管創(chuàng)作時(shí)是否參考或引用了他人的著作,,也不管該文獻(xiàn)以何種物質(zhì)形式出現(xiàn),均屬一次文獻(xiàn),。大部分期刊上發(fā)表的文章和在科技會(huì)議上發(fā)表的論文均屬一次文獻(xiàn),。上海信息化文獻(xiàn)知識發(fā)現(xiàn)
上海半坡網(wǎng)絡(luò)技術(shù)有限公司專注技術(shù)創(chuàng)新和產(chǎn)品研發(fā),,發(fā)展規(guī)模團(tuán)隊(duì)不斷壯大。公司目前擁有較多的高技術(shù)人才,,以不斷增強(qiáng)企業(yè)重點(diǎn)競爭力,,加快企業(yè)技術(shù)創(chuàng)新,實(shí)現(xiàn)穩(wěn)健生產(chǎn)經(jīng)營,。上海半坡網(wǎng)絡(luò)技術(shù)有限公司主營業(yè)務(wù)涵蓋計(jì)算機(jī)軟件,,網(wǎng)絡(luò)信息,技術(shù)咨詢,,技術(shù)服務(wù),,堅(jiān)持“質(zhì)量保證、良好服務(wù),、顧客滿意”的質(zhì)量方針,,贏得廣大客戶的支持和信賴。公司深耕計(jì)算機(jī)軟件,,網(wǎng)絡(luò)信息,,技術(shù)咨詢,技術(shù)服務(wù),,正積蓄著更大的能量,,向更廣闊的空間、更寬泛的領(lǐng)域拓展,。
- 安徽智慧導(dǎo)讀哪家好 2025-06-26
- 信息智慧導(dǎo)讀價(jià)格多少 2025-06-26
- 北京智慧導(dǎo)讀服務(wù) 2025-06-25
- 智慧導(dǎo)讀采購 2025-06-25
- 浙江智能化智慧導(dǎo)讀 2025-06-25
- 上海哪個(gè)智慧導(dǎo)讀 2025-06-25
- 上海智慧導(dǎo)讀多少錢 2025-06-25
- 運(yùn)營智慧導(dǎo)讀多少錢 2025-06-25
- 浙江智慧導(dǎo)讀收費(fèi)套餐 2025-06-25
- 福建智慧導(dǎo)讀特點(diǎn) 2025-06-25
- 青島香港留學(xué)機(jī)構(gòu) 2025-06-26
- 肥東第三方資質(zhì)代辦概況 2025-06-26
- 臨沂設(shè)計(jì)展廳設(shè)計(jì)公司 2025-06-26
- 東平數(shù)據(jù)智能營銷包括什么 2025-06-26
- 漢陽區(qū)勞動(dòng)爭議法律咨詢 2025-06-26
- 漢陽區(qū)焦慮心理咨詢平臺 2025-06-26
- 虎丘區(qū)綜合高新企業(yè)認(rèn)證新報(bào)價(jià) 2025-06-26
- 浦東新區(qū)方便貨物運(yùn)輸24小時(shí)服務(wù) 2025-06-26
- 防水防曬不變色木紋膜設(shè)計(jì)制作 2025-06-26
- 佛山修理物品報(bào)關(guān)報(bào)價(jià) 2025-06-26