哪些文獻知識發(fā)現(xiàn)承諾守信
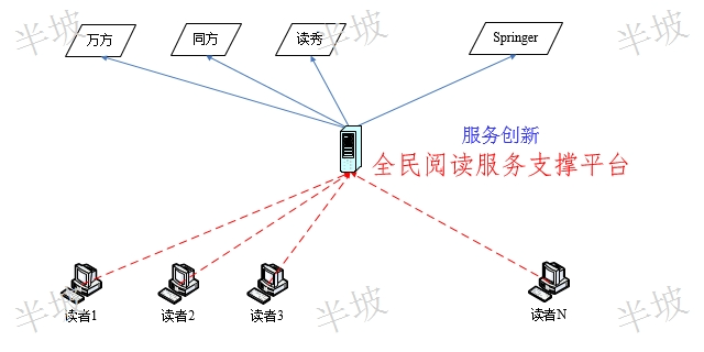
隨著圖書館數(shù)字文獻資源的規(guī)模越來越大,;數(shù)據(jù)庫品種數(shù)量越來越多,,;讀者服務(wù)的手段(遠程,、移動,、跨庫搜索等)也越來越多樣化,。但是,如何能使圖書館清晰了解讀者的閱讀行為,,優(yōu)化現(xiàn)有數(shù)字文獻館藏,,讓有限的數(shù)字資源采購資金發(fā)揮更大的讀者服務(wù)效益?其中,,哪些部門,、哪些讀者在使用?使用哪些文獻數(shù)據(jù)庫,?數(shù)字文獻利用統(tǒng)計在圖書館工作中,,越發(fā)顯得越為重要,。然而,數(shù)字圖書館目前服務(wù)現(xiàn)狀是:圖書館統(tǒng)一采購數(shù)字文獻資源,,圖書館的讀者各自分別訪問一個個的數(shù)字文獻資源數(shù)據(jù)庫?,F(xiàn)有的文獻數(shù)據(jù)庫-讀者文獻利用模式在示例的網(wǎng)絡(luò)拓撲中,我們很難確定圖書館所處的位置,。由此可見,,隨著讀者數(shù)字文獻需求不斷增長、文獻數(shù)據(jù)商蓬勃發(fā)展,,圖書館的服務(wù)功能卻正在逐步被邊緣化,。在上述文獻數(shù)據(jù)庫-讀者文獻利用模式中,常見的傳統(tǒng)計量評價方法包括:圖書館資源首頁數(shù)據(jù)庫進入次數(shù)統(tǒng)計,、文獻數(shù)據(jù)庫原廠商各自提供的訪問量/下載量報表等,。但實際情況是:這些數(shù)據(jù)很難真實反映讀者文獻數(shù)據(jù)庫的實際利用情況。數(shù)字圖書館通過利用新的科學(xué)技術(shù)來提高圖書館的功能,,增加圖書館的閱讀形式,。哪些文獻知識發(fā)現(xiàn)承諾守信
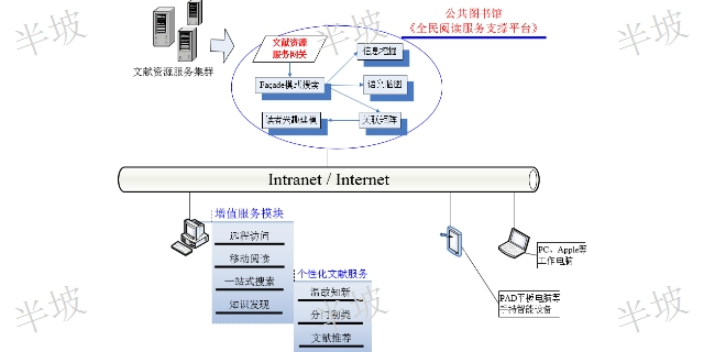
致匯一站式搜索特色:搜索數(shù)據(jù)庫類別選擇(期刊數(shù)據(jù)庫、論文,、**等類別),;單個文獻數(shù)據(jù)庫參與一站式學(xué)術(shù)搜索的選擇(可個性化自定義);默認全字段搜索(標題,、關(guān)鍵詞,、摘要、作者,、作者單位等),;可以限定搜索字段(標題、關(guān)鍵詞,、摘要,、作者、作者單位等),;可以設(shè)定搜索年代及跨度范圍,;多搜索詞組合檢索(具備與、或,、非等3種搜索算符),;跨語言同步搜索(中文搜索詞自動或手動轉(zhuǎn)換為對應(yīng)英文搜索詞);當讀者獲得初步檢索結(jié)果后,,還可以修正檢索式(二次檢索),,從而提供更精細的文獻查詢手段,,給讀者以更好的搜索體驗,。致匯一站式搜索從參與一站式學(xué)術(shù)搜索的文獻數(shù)據(jù)庫中直接獲取搜索結(jié)果(每個文獻數(shù)據(jù)庫的一次性返回結(jié)果數(shù)可以由系統(tǒng)管理員自定義)的搜索結(jié)果界面呈現(xiàn)4大部分:l界面上部的搜索結(jié)果文獻按年度劃分的時間軸柱狀圖點擊任意年代時間柱,,則界面中間的主體部分將顯示各個文獻數(shù)據(jù)庫搜索結(jié)果合并后(以去重)的該年度的文獻搜索結(jié)果。l界面左側(cè)是當前各個參與一站式學(xué)術(shù)搜索的文獻數(shù)據(jù)庫及其命中文獻數(shù)點擊任意文獻數(shù)據(jù)庫,,則界面中間的主體部分顯示該文獻數(shù)據(jù)庫的命中文獻詳情,。這里是原始文獻數(shù)據(jù)庫的搜索結(jié)果順序。智能化文獻知識發(fā)現(xiàn)聯(lián)系方式將傳統(tǒng)統(tǒng)計質(zhì)量控制中的事后檢驗轉(zhuǎn)變?yōu)槭孪?預(yù)測,,重點是揭示隱藏在其中的有價值的模式和知識,。
文獻的意義:作為一種具體而特殊的元研究,文獻綜述是學(xué)術(shù)研究乃至學(xué)術(shù)創(chuàng)新的基石,。俗話說,,"站在巨人的肩膀上能比巨人看得更遠"。學(xué)者首先要學(xué)會 "敘事",,即了解前人的知識積累,,描述他人在自己關(guān)心的問題上的成就。文獻對人類文明和社會進步非常重要,。無論古代還是現(xiàn)代,,無論中國還是外國,任何從事科學(xué)研究的人都需要依靠相關(guān)的文獻,。它是科學(xué)研究的基礎(chǔ),,是人類知識寶庫的一個組成部分,是人類的共同財富,。它的內(nèi)容反映了人們在一定社會和歷史階段的知識水平,。
隨著科學(xué)技術(shù)的進步,經(jīng)濟,、文化的發(fā)展和社會需求的增加,,現(xiàn)代文獻有了較大的發(fā)展,呈現(xiàn)如下特征:(1)發(fā)展迅速,,數(shù)量劇增,。據(jù)統(tǒng)計,全世界每年出版的圖書,、期刊,、科技報告、專利文獻等各種文獻的總量幾乎每10年增加1倍(見文獻增長),。(2)類型復(fù)雜,,品種多樣。除傳統(tǒng)的圖書,、期刊,、報紙外,出現(xiàn)了各種報告,、會議錄,、學(xué)位論文,、專利文獻等;文獻載體除傳統(tǒng)的印刷型文獻外,,出現(xiàn)了音像型,、縮微型、機讀型的文獻,,且有與印刷型文獻相抗衡的趨勢,。(3)分布不均,內(nèi)容重復(fù),。由于現(xiàn)代科學(xué)的交叉和互相滲透,,致使某一學(xué)科領(lǐng)域的文獻既大量集中在一小部分專業(yè)書刊上,又有相當數(shù)量的文獻分散在眾多的相關(guān)學(xué)科領(lǐng)域的書刊中(見文獻分布定律),;在各學(xué)科及各相關(guān)學(xué)科之間,,大量文獻交叉重復(fù),造成文獻“冗余”(見情報冗余),。(4)出版周期長,,老化加速。由于人們認識事物的能力不斷增強,,使文獻增長速度快于發(fā)表,、刊載它們的書刊的增長速度,致使大量文獻從成文到正式出版的“時差”增大,;由于現(xiàn)代科技的迅猛發(fā)展,,知識更新速度加快,文獻老化速度也相應(yīng)加快,,尤其在自然科學(xué)領(lǐng)域,,很多文獻幾年后就陳舊過時(見科學(xué)文獻老化)。文獻是重要的信息資源,。 1809920 上海半坡的數(shù)字圖書館為授權(quán)讀者提供遠程文獻閱讀和移動閱讀服務(wù),。
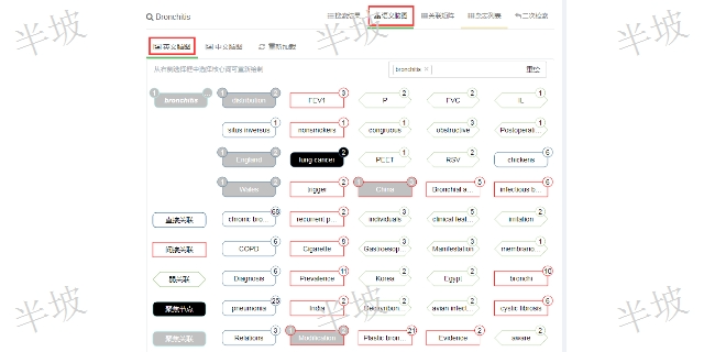
文獻知識發(fā)現(xiàn)是一個涉及從大量文獻中提取、整合和分析知識的復(fù)雜過程,。文獻知識發(fā)現(xiàn)是指從公開發(fā)表的文獻中發(fā)現(xiàn)某些知識片段間的隱含聯(lián)系,,并在此基礎(chǔ)上提出科學(xué)假設(shè)或猜想,引導(dǎo)科研人員進行攻關(guān)或?qū)嶒?,從而發(fā)現(xiàn)新知識,。這一概念由Swanson教授在1986年提出,它基于一個事實:記錄性知識(文獻)總量與人類吸收知識能力之間的鴻溝巨大且不斷擴展,,同時知識分裂(分化)現(xiàn)象日趨嚴重,,跨學(xué)科、跨專業(yè)的知識交流導(dǎo)致各個學(xué)科不斷產(chǎn)生新的分支和專業(yè),使得文獻中隱含的關(guān)系不易被發(fā)覺,。文獻知識發(fā)現(xiàn)是一個涉及多個方面和環(huán)節(jié)的復(fù)雜過程,。通過加強文獻篩選和評估、提升數(shù)據(jù)挖掘技術(shù),、培養(yǎng)跨學(xué)科人才等措施,,我們可以更好地應(yīng)對挑戰(zhàn)并推動文獻知識發(fā)現(xiàn)的發(fā)展和應(yīng)用,。邏輯上的串聯(lián)是在訪問目標前面添加一個文獻中介服務(wù)網(wǎng)關(guān)地址,。北京文獻知識發(fā)現(xiàn)價格
知識轉(zhuǎn)化為能力,知識真正成為生產(chǎn)力,,讀者在知識的指引下進行知識的深層次學(xué)習(xí)與研究,。哪些文獻知識發(fā)現(xiàn)承諾守信
文獻知識發(fā)現(xiàn)是一個涉及信息檢索、數(shù)據(jù)挖掘和知識管理的過程,,旨在從海量的文獻資源中提煉出有價值的知識,。這個過程不僅關(guān)注文獻的表面信息,更深入地挖掘文獻內(nèi)部的關(guān)聯(lián),、趨勢和模式,,從而揭示出隱藏在其中的知識。在文獻知識發(fā)現(xiàn)的過程中,,首先需要進行的是信息檢索,。這通常涉及到利用關(guān)鍵詞、主題詞或其他標識符,,在特定的文獻數(shù)據(jù)庫或知識庫中進行搜索,。通過這種方法,可以初步篩選出與特定研究主題或問題相關(guān)的文獻**,。接下來,,數(shù)據(jù)挖掘技術(shù)被用于深入分析這些文獻。這包括使用文本挖掘技術(shù)提取文獻中的關(guān)鍵信息,、主題或觀點,,利用統(tǒng)計分析方法揭示文獻之間的關(guān)聯(lián)和趨勢,以及應(yīng)用機器學(xué)習(xí)算法識別文獻中的模式和異常值,。通過這些分析,,可以進一步提煉出文獻中的深層知識和見解。哪些文獻知識發(fā)現(xiàn)承諾守信
- 什么是科研學(xué)術(shù)助手價格多少 2025-05-29
- 綜合科研學(xué)術(shù)助手是什么 2025-05-29
- 運營科研學(xué)術(shù)助手價格多少 2025-05-28
- 運營科研學(xué)術(shù)助手簡介 2025-05-28
- 綜合科研學(xué)術(shù)助手發(fā)現(xiàn) 2025-05-28
- 品牌科研學(xué)術(shù)助手案例 2025-05-28
- 哪些科研學(xué)術(shù)助手承諾守信 2025-05-28
- 咨詢科研學(xué)術(shù)助手大概價格多少 2025-05-28
- 哪些科研學(xué)術(shù)助手采購 2025-05-27
- 提供科研學(xué)術(shù)助手案例 2025-05-27
- 新吳區(qū)專業(yè)護工多少錢 2025-05-29
- 湖北電子簽咨詢熱線 2025-05-29
- 常州散熱器焓差實驗室銷售 2025-05-29
- 松江區(qū)保潔外包聯(lián)系人 2025-05-29
- 上海市異地患者陪診小程序 2025-05-29
- 黑龍江填埋場相關(guān)檢測與評估平臺 2025-05-29
- 無錫業(yè)務(wù)前景數(shù)字創(chuàng)意產(chǎn)品展覽展示服務(wù)選擇 2025-05-29
- 第三十九屆廣東國際陶瓷工業(yè)展技術(shù)論壇 2025-05-29
- 南昌橡膠高壓軟管 2025-05-29
- 哪個拓客軟件服務(wù)電話 2025-05-29